

Written by Hugh Han
Fortunately, Valon’s business, loan count, and product maturity have grown over the past few years. Between the beginning of 2022 and now, Valon has increased its loan count from ~16,000 to ~300,000, number of batch process types from 20 to 282, and it has launched Lending and Insurance offerings.
However, as Valon has grown over the years, Valon’s data layer has also experienced increased throughput that has pushed our single-instance data layer to its limits. A constant challenge at Valon is scaling our data layer to support this ever-increasing growth.
Some solutions on our immediate roadmap include sharding our database and introducing read replicas. However, before tackling these relatively heavyweight solutions, we looked for some easy wins with an outsized impact.
This blog post walks through the exploration, design, and instrumentation of database read memoization as one of the many solutions to increase maximum throughput from the application layer to the data layer.
Narrowing Down a Problem
With a goal of increasing the maximum throughput of the data layer, the problem statement is ambiguous—and attempting to define the solution space for an ambiguous problem can be dangerous. Hence, the first step is to narrow down a specific problem.
We can start from first principles and observe our data layer traffic patterns.
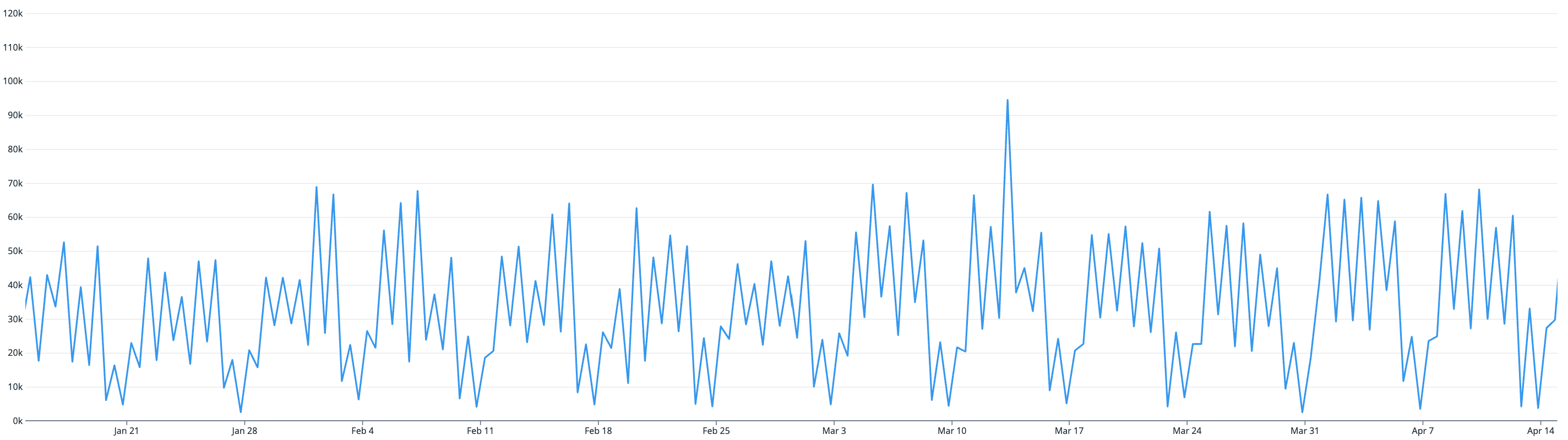
MySQL reads/sec
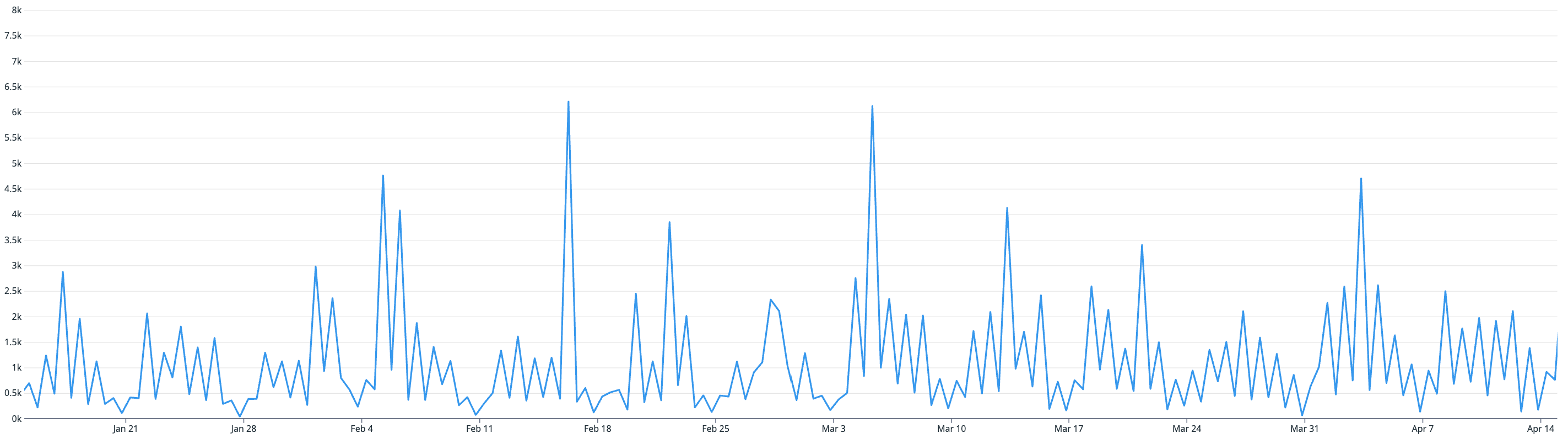
MySQL writes/sec
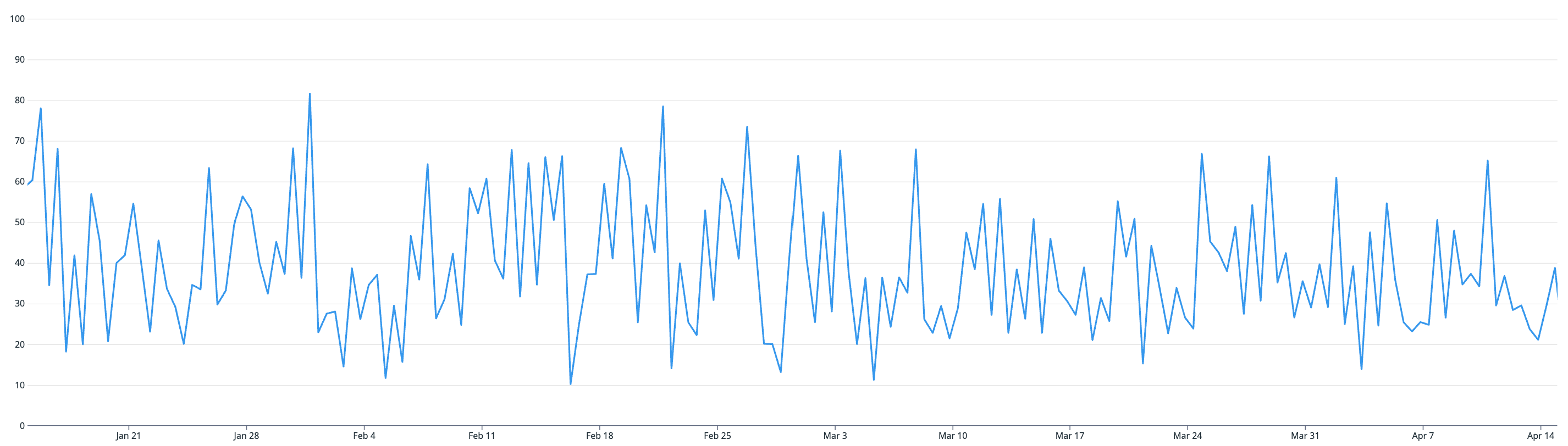
MySQL read/write ratio
After observing our data layer traffic patterns (noting an average read/write ratio of ~30:1) over a 3-month period between January and April, we can draw some correlations with our CPU utilization pattern.
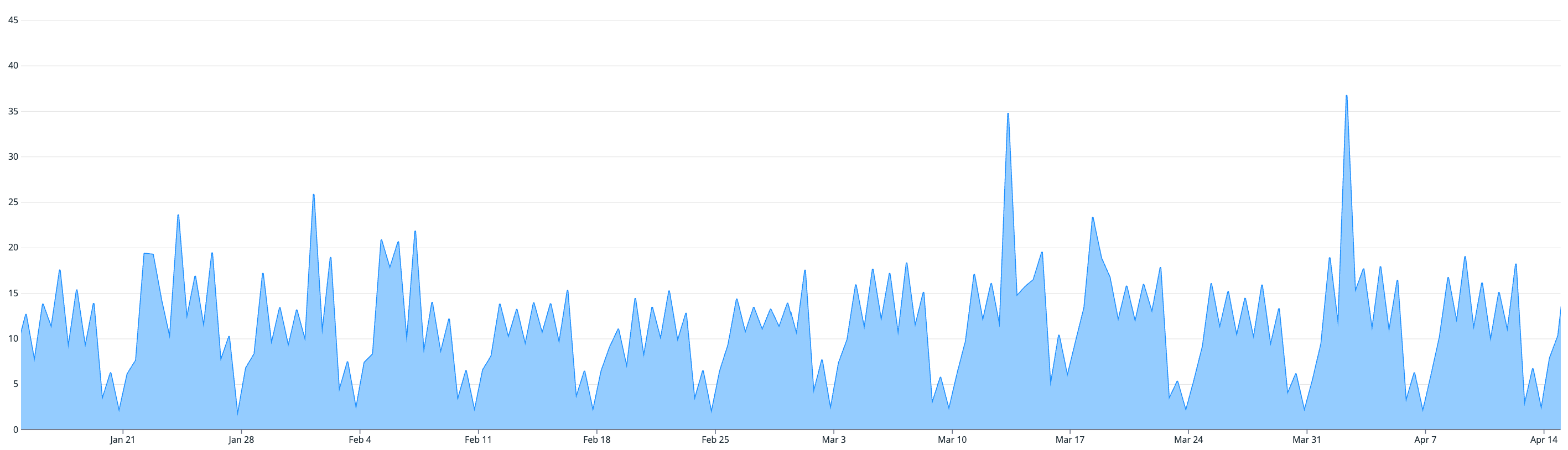
MySQL CPU utilization (%)
We know that the CPU utilization of our database is directly correlated with the latency of our queries and inversely correlated with the reliability of our queries. And from the graphs above, we can see that the CPU utilization of our database is directly correlated with our read traffic (likely due to our high read/write ratio).
Hence, a narrowed down problem statement could be phrased as, “The anticipated growth of our company by x over the next two years will prevent our data layer from meeting downstream SLAs.”
Defining the Solution Space
With the problem statement more clearly defined, we can begin considering the solution space. When considering all possible solutions, we must ask ourselves:
To what extent does each solution solve the problem?
Does each solution move us in the correct direction?
Additionally, we must also consider the following constraints, which cannot be compromised.
ACID Properties
Our existing ACID properties include read-after-write consistency and the REPEATABLE READ isolation level. These properties are crucial; our business logic depends on the consistency of what is “true” from the perspective of a single application worker. Hence, compromising these properties would have downstream effects with respect to assumptions made in our application layer, and impact correctness.
Developer Experience
Making any changes to the developer experience whatsoever is undesirable, as we want keep obstacles to a minimum to empower our engineers to be as productive as possible. The ideal solution would allow us to increase the maximum data layer throughput in a way that is completely abstracted away from application engineers.
Read Memoization Exploration
One of the solutions we considered—the subject of this blog post—was database read memoization. Memoization is a convenient way to avoid database reads completely for queries that have already been queried, so long as it does not violate our aforementioned ACID properties. This made memoization especially appealing, because we knew that it was common for single requests and offline scripts in our application layer to query the same row(s) in the data layer multiple times.
Furthermore, memoization is relatively straightforward to analyze and reason about; i.e., achieving a memoization rate of k would imply a reduction of read traffic to the database by k.
If you’re interested in these problems and joining Hugh as part of Valon’s team, check out our open career opportunities.
The following Python snippet illustrates the behavior of this memoization algorithm using a cache.

There is an obvious drawback to this algorithm: its inability to leverage memoization while a read/write transaction is active. Despite this, we chose this algorithm because supporting memoization while read/write transactions are active (e.g., multiple read/write transactions are opened and closed in a staggered/nested pattern at various points in time)—while continuing to meet our existing ACID properties—would greatly increase the complexity of the algorithm. We wanted an initial algorithm with which we could easily reason about, quickly test our hypothesis, and iterate upon.
Selecting the Caching Layer
After devising a simple memoization algorithm, the question that followed was: “In which layer should the cache used to implement memoization exist?”
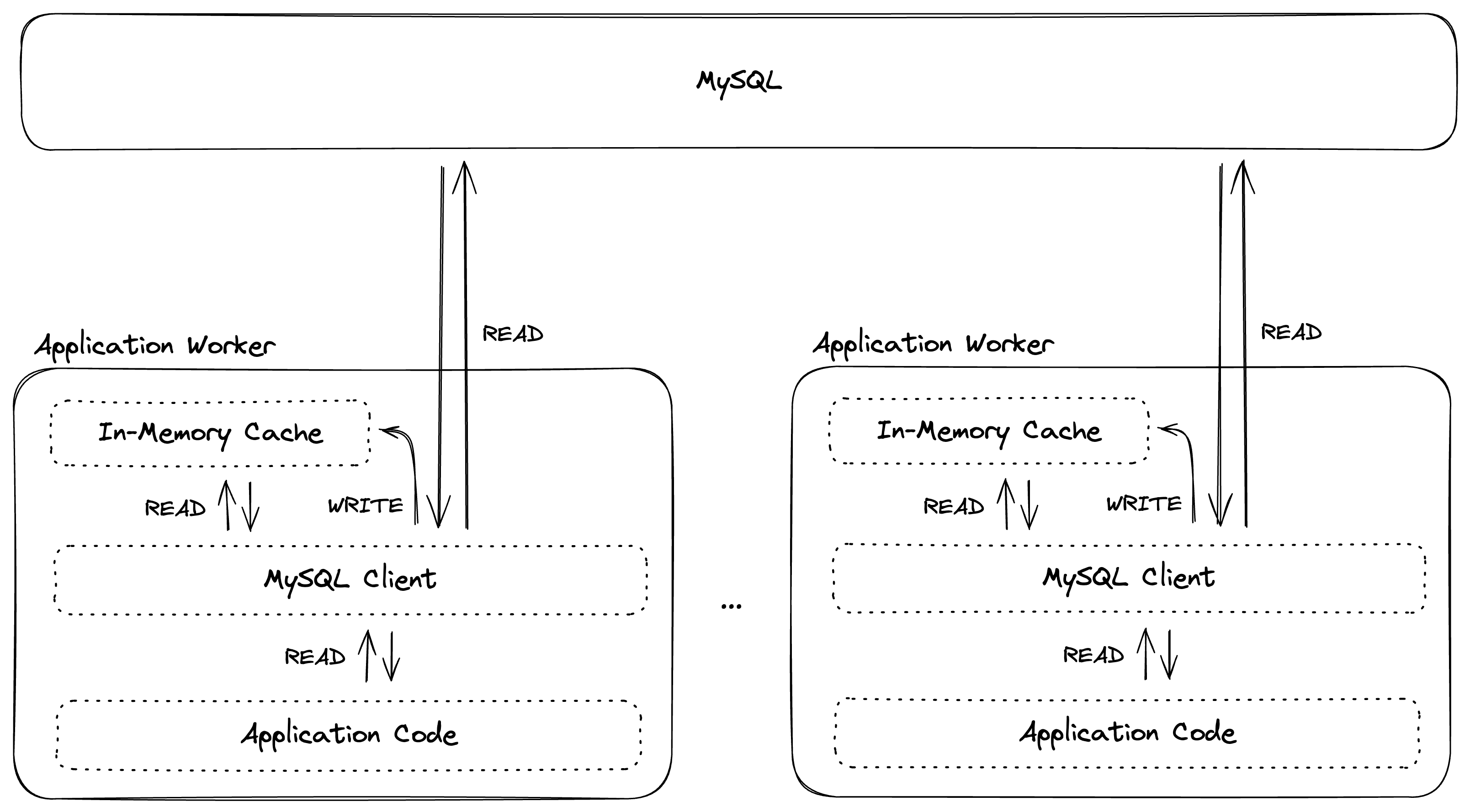
The first option we considered was multiple in-memory caches embedded within each application worker.
The next option we considered was a single cache that would be shared among all application workers (e.g., Memcached/Redis), in a layer in between the application layer and the database.
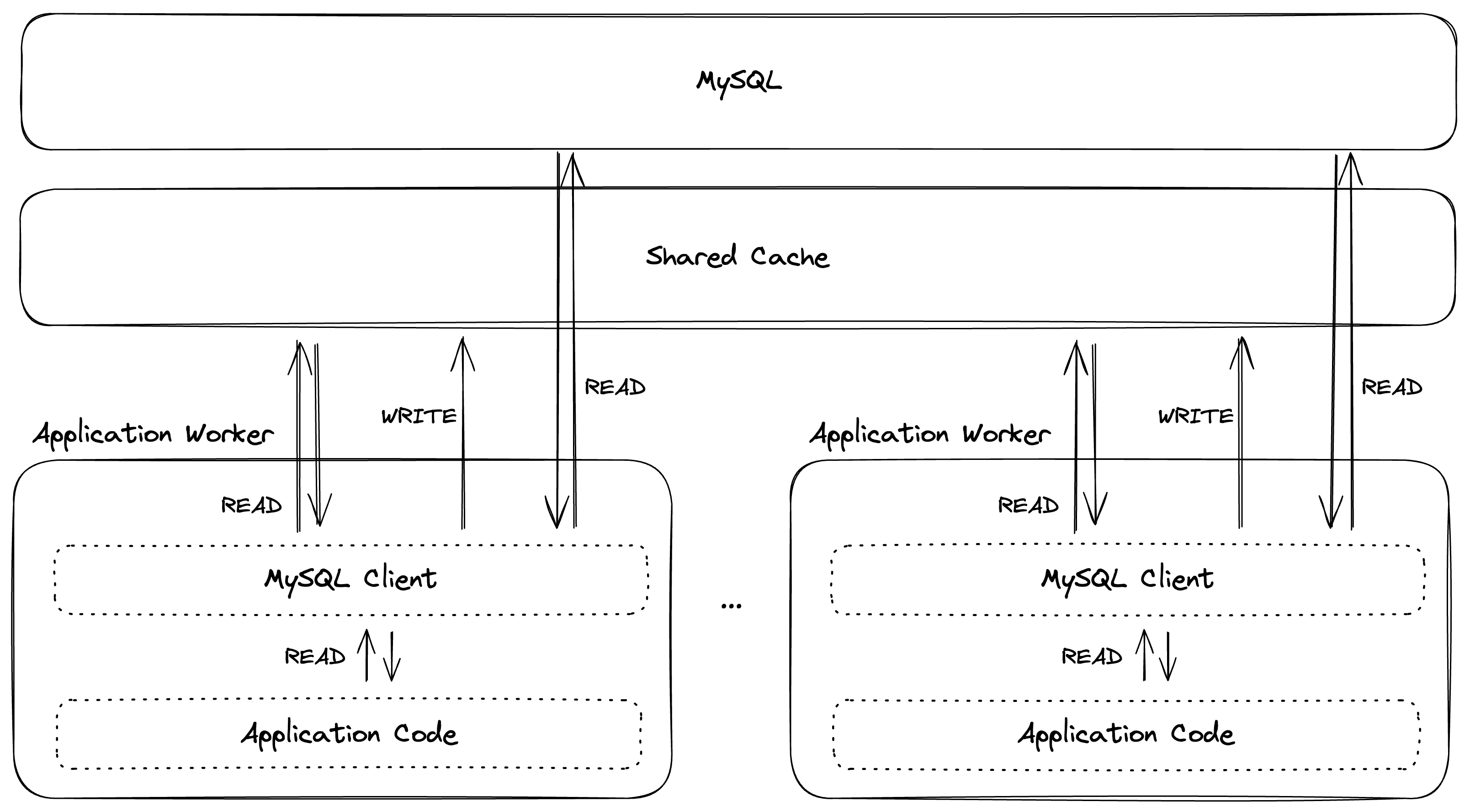
It turns out that implementing our simple memoization algorithm becomes complex pretty quickly with a shared cache. The algorithm could be evolved such that only relevant entries are cleared when writes occur (rather than clearing all entries when a read/write transaction begins); but as mentioned above, we wanted as simple of an initial algorithm as possible.
Furthermore, the most frequent data access patterns within our application layer involve iterating over a large range of entities, and performing sets of operations on those entities. This implies that our most frequent data access patterns do not have hotspots, which conceptually makes a shared cache less compelling. Moreover, recall that our most frequent data access patterns involve querying for the same row(s) multiple times within the same request or script. This suggests that an in-memory cache local to each application worker could be effective.
Lastly, building out a shared cache layer is something we predicted could be an incremental improvement to the design involving embedded, in-memory caches.
For all of these reasons, we decided to begin exploring the extent of how positively a database read memoization solution using local, in-memory caches could affect our data layer, before potentially prematurely optimizing our design.
Estimating Impact, Part 1
After forming a general idea of how we could proceed, we wanted to collect some data to understand the percentage of read queries that would be memoized by our proposed solution. If the percentage were to be high enough, it would provide evidence supporting our initial hypothesis that some form of database read memoization would make progress towards solving our problem statement.
To begin, we wanted to emit a coarse-grain metric that would provide us with an initial estimate of the impact without sinking too much upfront effort in preliminary refactors or implementation details of the memoization algorithm. This allowed us to hit the ground running, introducing a minimal amount of change to the codebase and getting a rough idea of how the algorithm would perform. The coarse-grain metric would measure memoization rate using an algorithm that only clears each cache when a write happens, rather than an algorithm that additionally clears and disables the cache while there exists at least one active read/write transaction.
For additional safety measures, the experiment itself was gated behind a feature flag that would allow us to immediately turn it off if anything went awry.

After a week of observing the coarse-grain metric, we estimated a memoization rate of ~39%. This was a non-negligible impact for such a simple, non-invasive solution.
Next, it was time to tune our metric to get a more accurate estimate of how the memoization would perform if it were actually implemented. To do this, we would begin executing on the preliminary work and solution.
Preliminary Work
Before we could build the solution, we had to take on some preliminary work. Our codebase was using read/write transactions everywhere, including for business logic that did not need to perform writes. This meant that our proposed algorithm would be useless, given that it clears and disables the cache every time a read/write transaction is active. In order to leverage our algorithm effectively, we would need to migrate our entire codebase of ~1.5 million lines of Python to using read-only transactions wherever possible.
This was done by implementing a static analysis tool that would construct abstract syntax trees (ASTs) from input Python files, and afterwards output the line numbers corresponding to database read/write transactions that only perform queries that do not modify or lock transactional tables (i.e., SELECT queries, excluding SELECT ... FOR UPDATE queries).
We added the static analysis tool to our internal peach tool—a command line interface (CLI) used to run commands for developer velocity (e.g., type-checkers, formatters, and code generators), which could be invoked via peach check --db-sessions. The optional --changed or --all flags (defaulting to --changed) would tell the command to check changed files or all files, respectively.
An example invocation of this tool over the entire codebase would have looked as follows.

Once this tool was implemented, we used it to migrate flagged call-sites to use read-only transactions, as opposed to read/write transactions.
Building the Read Memoization Solution
Once the preliminary work was done, it was time to begin implementing the read memoization solution.
Cache Configuration
The initial cache was configured with a TTL of 1 second. The TTL was chosen to be this value because a relatively low value minimizes the frequency of stay-alive, read-only polling scripts continuously fetching stale data and closely models our preexisting behavior of not having database read memoization. A low value would allow us to be initially conservative, without preventing us from performing experiments in the future to optimize the value.
In addition, the initial cache was configured with a size of 1 GB to reduce the likelihood of encountering out-of-memory (OOM) errors.
These configurations were explicitly not exposed in any sort of interface in order to align with our goal of keeping the developer interface as simple as possible.
Disabling Memoization
We wanted to be extra careful in the case that we were unaware of specific call-sites that required memoization to be disabled that (i.e., read-only workers that require sub-second data freshness). Due to our cache TTL of 1 second, such call-sites would fail to deliver that sub-second data freshness if using data layer memoization. Hence, we decided to implement an interface to explicitly turn off database read memoization for particular execution contexts, if it were necessary to do so.
To do this, we introduced a new DatabaseConfig object that could be set in all entry points (e.g., HTTP endpoints, offline scripts), which would get propagated to all call-sites necessary and be used to determine whether memoization would be enabled.

Monitoring + Observability
As we were building a piece of middleware that would intercept all requests from the application layer to the data layer, it was extremely important to have the proper monitoring and observability in place to allow us to be aware of the health of our new piece of middleware.
The metrics we introduced were:
distribution of query compilation latency,
distribution of query hash latency,
count of cache write attempts (with tags on failure/success), and
count of MySQL client reads (with tags on memoized or non-memoized).
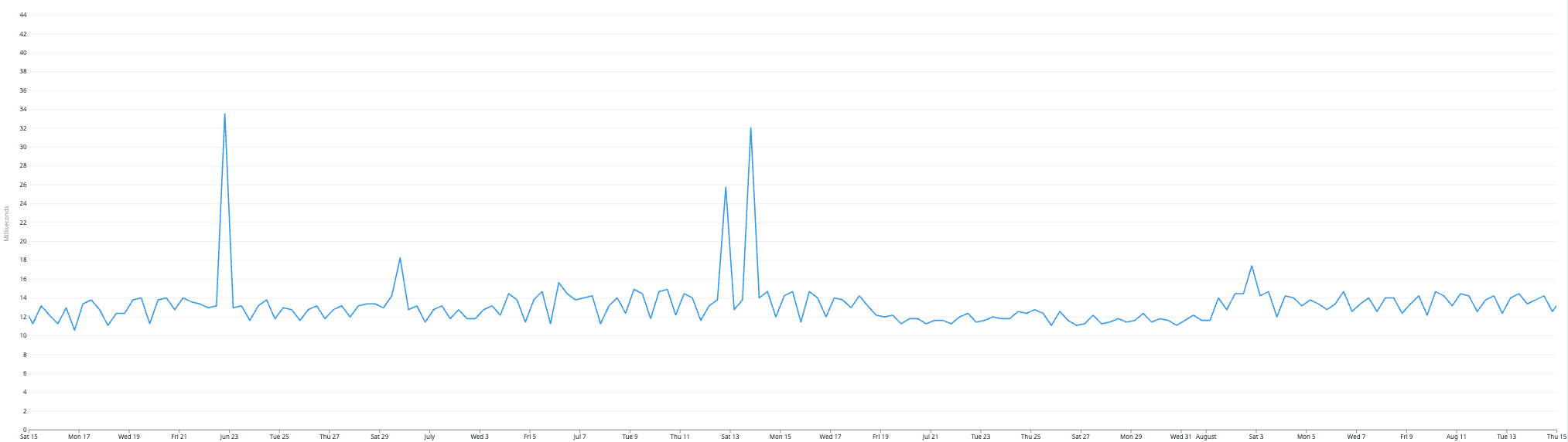
P99 Query Compile Latency
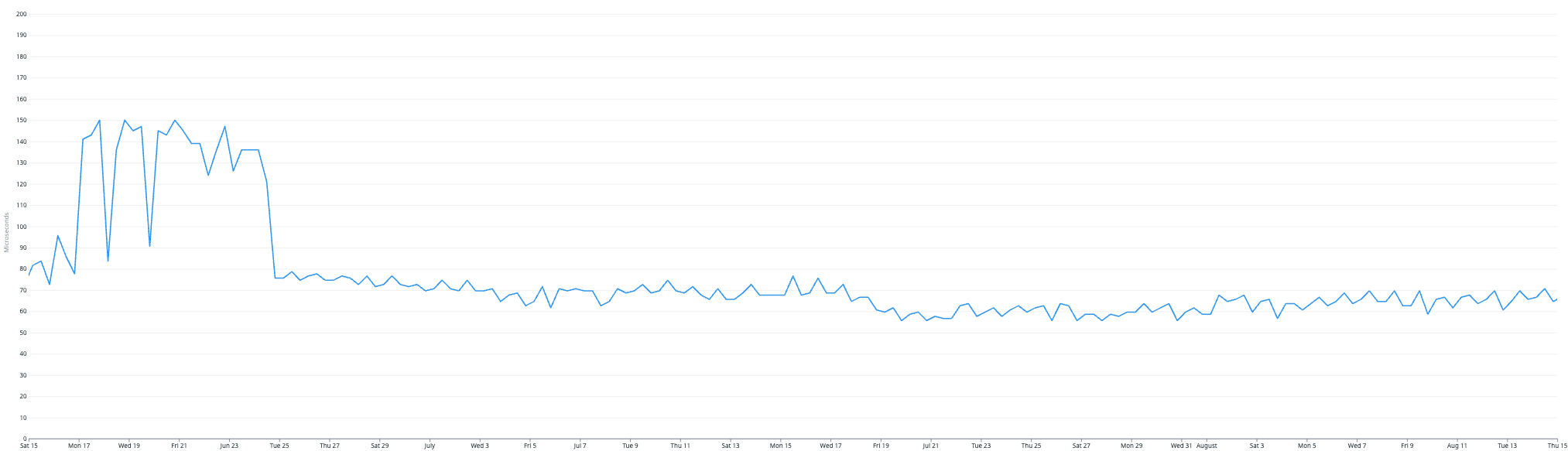
P99 Query Hash Latency
The threshold alerts we introduced monitored:
P99 query compilation latency,
P99 query hash latency, and
the number of failed cache write attempts.
Estimating Impact, Part 2
After we had a solution implemented with observability in place, we could begin estimating the impact of our solution at a finer-grained level. The plan was to emit metrics that simulated the use of database read memoization, without actually using the results from the memoization algorithm for anything. After a week of experimentation, we observed an estimated memoization rate of ~29%—a bit worse than our coarse-grain estimate of ~39%, but non-negligible nonetheless.
Rollout
With enough supporting evidence of the impact of our solution, it was time for a slow rollout. The exact rollout schedule was announced to each engineering team in their respective Slack channels for transparency.
The aforementioned DatabaseConfig.is_database_read_query_memoization_enabled flag was used to control rollout in different entry points within our application layer (e.g., HTTP endpoints, scripts), with an additional feature flag that could immediately turn off memoization everywhere in the case of a potential incident.
After about a month, we had rolled out the database read memoization solution everywhere in our application layer.
An Edge Case Overlooked
The rollout was not without hiccups, however. The initial implementation of the database read memoization solution was not thread safe; i.e., specific race conditions with respect to the opening and closing of database transactions by multiple threads on the same application worker would allow the cache to be enabled when it should be disabled in particular scenarios, because the cache is shared across multiple threads.
This issue manifested during our rollout, when application entry points unexpectedly attempted to read from the cache when it was disabled, causing exceptions to be raised.

To solve this, we implemented a lock that would be acquired when disabling or enabling the cache.
Measuring Impact
After the database read memoization solution was rolled out to 100% of all traffic within our codebase, we were able to use the observability we built to measure some impact.
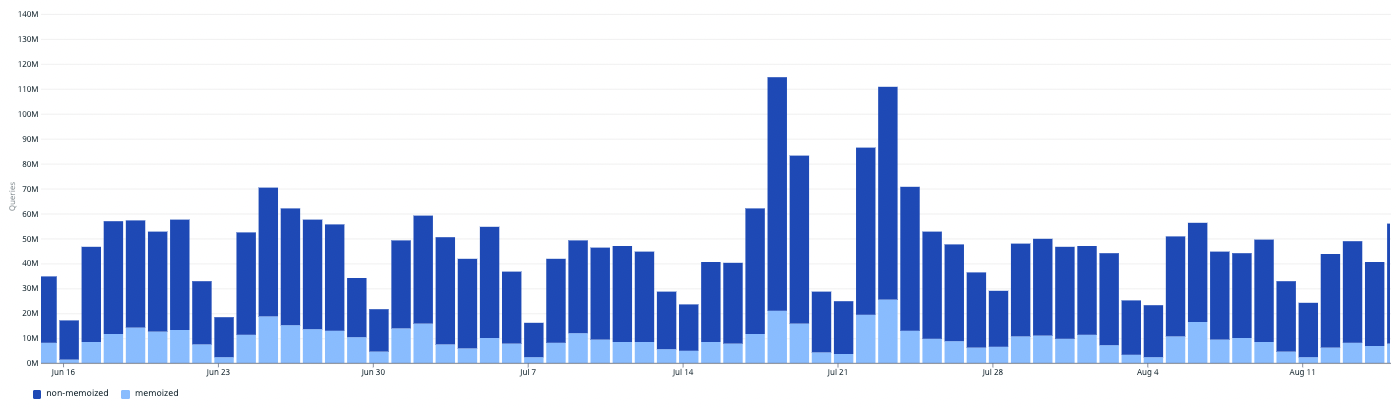
MySQL client read count, non-memoized vs memoized
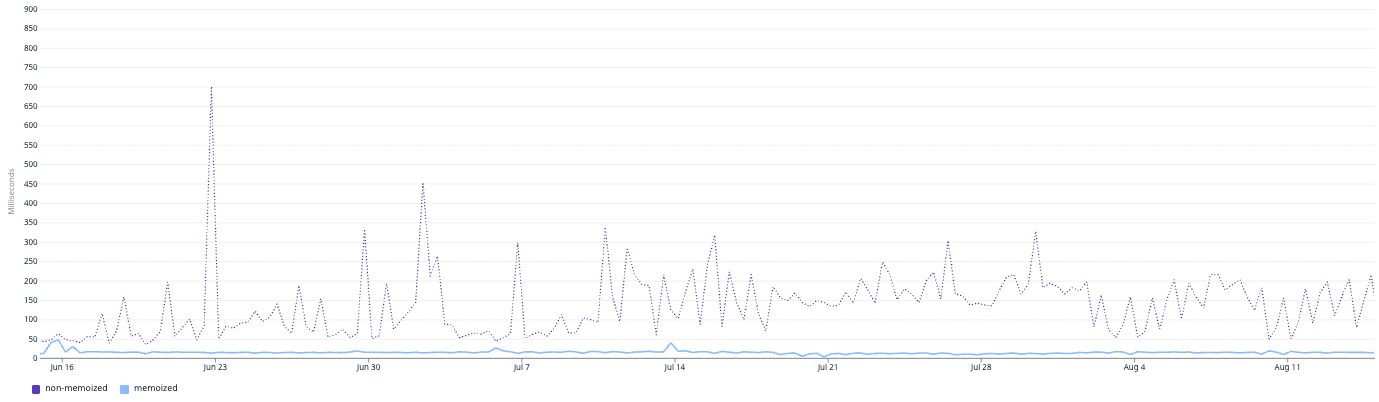
P99 MySQL client read latency, non-memoized vs memoized
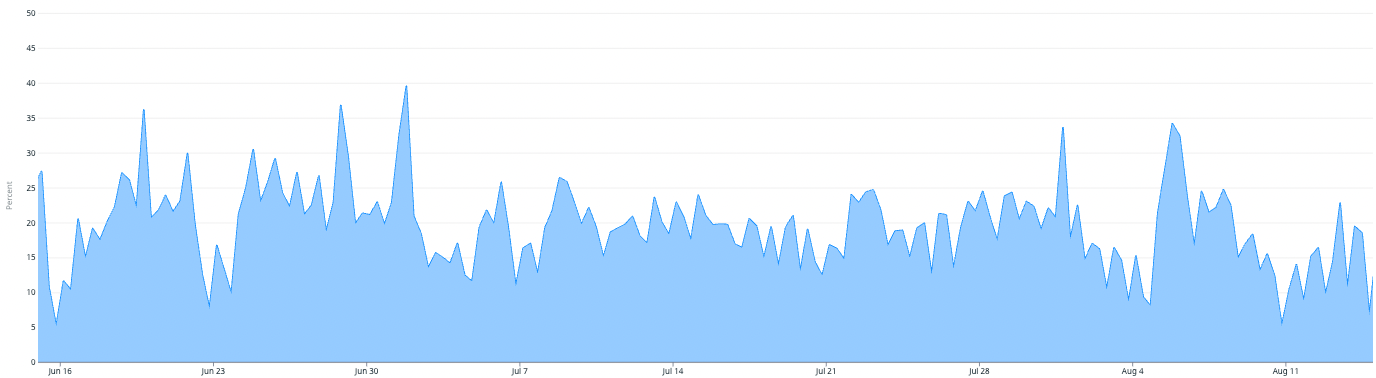
MySQL client memoization rate
Over a longer period of two months, we observed a memoization rate of ~21% of all read traffic to our data layer, with an additional side effect of significantly lower query latency for memoized queries.
Concluding Remarks
The solution described in this blog post was low-lift, low-cost, and contributed quantifiable impact towards a relatively large problem statement, without introducing significant complexity into our system or downstream effects to our application engineers.
Future Work
Before extending the database read memoization solution any further, we plan to begin iterating on different solutions that aim to tackle the same problem statement. In particular, these solutions include:
sharding our single-instance database,
introducing read replicas into our data layer, and
introducing mechanisms to more evenly distribute work over time to our data layer.
That being said, there are some iterative improvements to be made to the database read memoization solution and the related tooling discussed in this post. Such improvements include:
optimizing the configuration values set for our cache,
improving the read memoization algorithm for a higher memoization rate,
query compilation caching to further reduce query latency, and
maturing the
peach check --db-sessionstool.
We’re Hiring!
Interested in joining us and working on our data layer or other interesting challenges? We’re hiring!
Acknowledgements
Special thanks to Jay Chen, Paul Veevers, and Preston Chan for their contributions to this project.
